


Gemini 3 來了!Google 新一代 AI 模型已不再是輔助工具,而是主動的思考與規劃夥伴,模型智慧更是「階躍式提升」,目的是協助專業人士「實現任何創意」。
Gemini 3 是 Google 最新的 AI 模型系列,而 Gemini 3 Pro(目前在 AI Studio 中已能免費使用) 則是該系列中第一個發布且功能最強大的模型。Google 計劃在未來很快發布 Gemini 3 系列的其他模型。

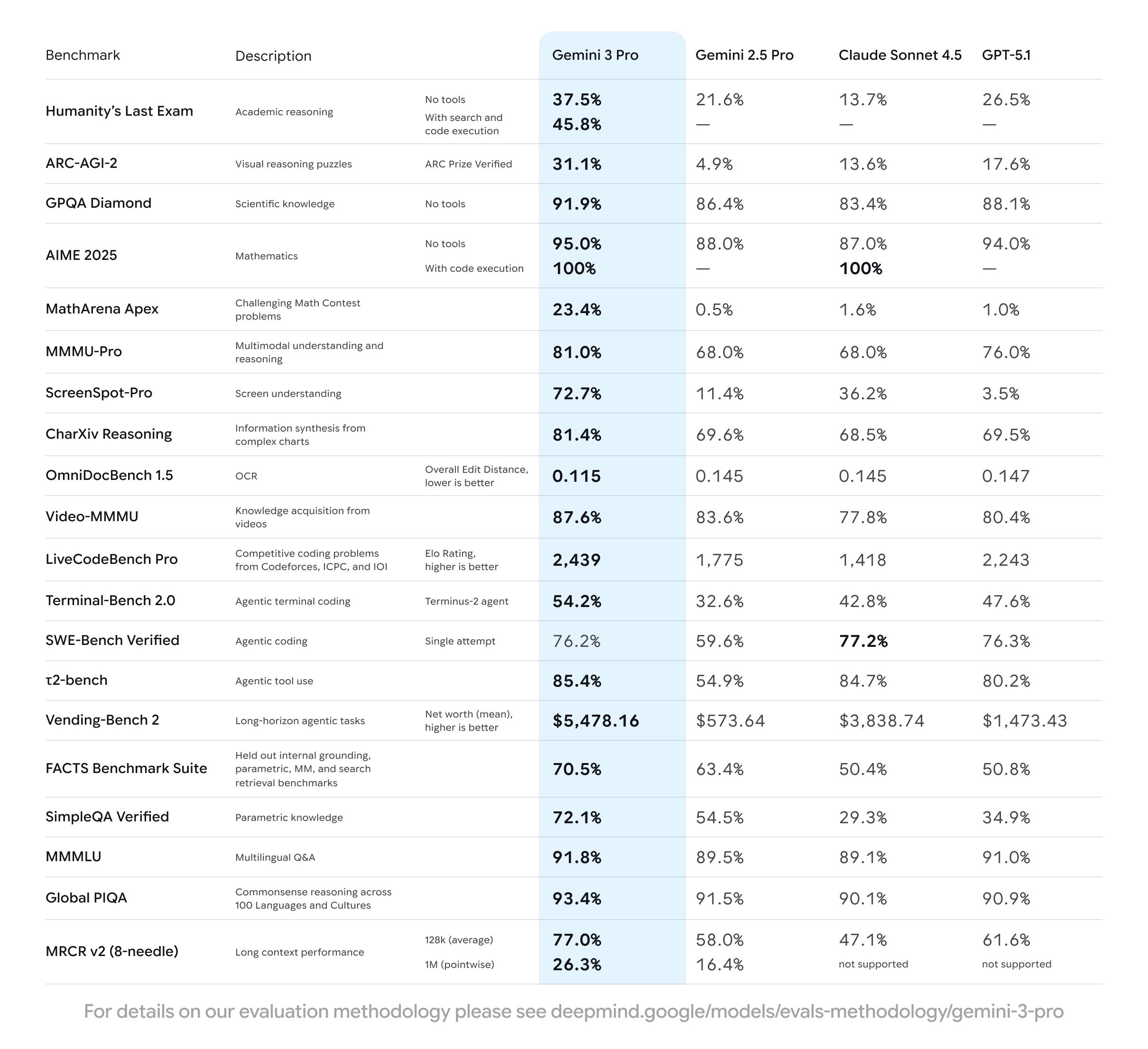
Gemini 3 的核心優勢,在於具備的前所未有的深度推理能力。在複雜的科學知識測試(如 GPQA Diamond)中,Gemini 3 Pro 獲得 91.9% 的高分,展現出博士級的推理能力。
此外,Gemini 3 Pro 最讓有感的功能之一,是從自動規劃旅遊行程、整理 Gmail 收件匣,到在全新的 Google Antigravity 平台中自主執行複雜的端對端軟體開發任務,Gemini 3 轉變為積極的合作夥伴,更好地協助開發者和管理者。
Gemini 3 發布後,Gemini 也迎來了史上最高的訪問量。根據 Similarweb 公布的數據,單日訪問量突破歷史記錄,從約 4400 萬暴增至約 5400 萬。

《經理人》深入分析 Gemini 3 如何透過這些突破性的技術,幫助團隊釋放前所未有的生產力,並在快速變化的商業環境中,保持競爭優勢。
1. Gemini 3 是什麼?
Gemini 3 是 Google 迄今為止最智能的 AI 模型系列,以最先進的推理技術為基礎建構而成;Gemini 3 整合 Gemini 的所有能力,協助使用者實現任何創意 (bring any idea to life)。
Gemini 3 Pro 是 Gemini 3 系列的首個模型,最適合處理複雜工作,特別是需要廣泛世界知識和跨模式進階推理能力的工作。
2. Gemini 3 與其他 AI 助手如 ChatGPT 有何不同?
Gemini 3 Pro 在每一項主要的 AI 基準測試中,表現都顯著超越先前的版本,並在多個關鍵領域樹立了新標準:
| 基準測試 | Gemini 3 Pro (分數/Elo) | GPT-5.1 (分數/Elo) | Claude Sonnet 4.5 (分數/Elo) |
|---|---|---|---|
| LMArena 排行榜 | 1501 Elo (榜首) | — | — |
| 競賽編碼問題 (LiveCodeBench Pro) | 2,439 Elo | 2,243 Elo | 1,418 Elo |
| 多模態理解 (MMMU-Pro) | 81.0% | 76.0% | 68.0% |
| 科學知識 (GPQA Diamond) | 91.9% (未使用工具) | 88.1% | 83.4% |
此外,Gemini 3 在設計上具備更強的深度與細微差異的掌握能力,能提供聰明、簡潔且直接的回應,提供真知灼見,而非陳腔濫調。
3. Gemini 3 和先前的版本相比,有哪些突破和提升?
Gemini 3 是建立在先前版本的基礎上,整合了所有能力。
如果將 AI 模型比喻為處理訊息的「廚師」,那麼 Gemini 2 就像一個技藝精湛,懂得如何使用各種廚房工具(代理能力)的廚師。
Gemini 3 則像一位米其林星級主廚,他不僅技藝更精湛(最先進的推理),還能處理和融合所有類型的食材——文字、圖像、影片、音訊(世界領先的多模態理解)。
此外,Gemini 3 能根據顧客的需求,即時設計並建構出獨特的用餐環境和工具(生成式介面),並能自主規劃連續數天的複雜菜單(代理能力和長期規劃),確保每次上菜都能提供深刻的見解(深度與細微差異)。
| 突破和提升領域 | Gemini 3 的主要進展 |
|---|---|
| 推理能力 | 具備最先進的推理能力,能掌握前所未有的深度和細微差異。在所有主要 AI 基準測試中,表現皆顯著超越 2.5 Pro。 |
| 代理人與工具使用 | Gemini 2 奠定了代理能力的基礎,而 Gemini 3 帶來了更卓越的指令遵循與更有意義的工具使用。在代理編碼和長期代理任務上表現優異。在衡量編碼代理能力的 SWE-bench Verified 中,得分 76.2% (大幅超越 2.5 Pro 的 59.6%)。 |
| 編碼性能 | 超越 Gemini 2.5 Pro,擅長代理式工作流程和複雜的零樣本任務 (zero-shot tasks)。在 Terminal-Bench 2.0 上得分 54.2%,大幅高於 Gemini 2.5 Pro 的 32.6%。 |
| 長脈絡視窗 | 支援 100 萬個詞元的輸入脈絡窗口。Gemini 3 Pro 在長脈絡性能(MRCR v2, 128k 平均)上得分 77.0%,遠高於 Gemini 2.5 Pro 的 58.0%。 |
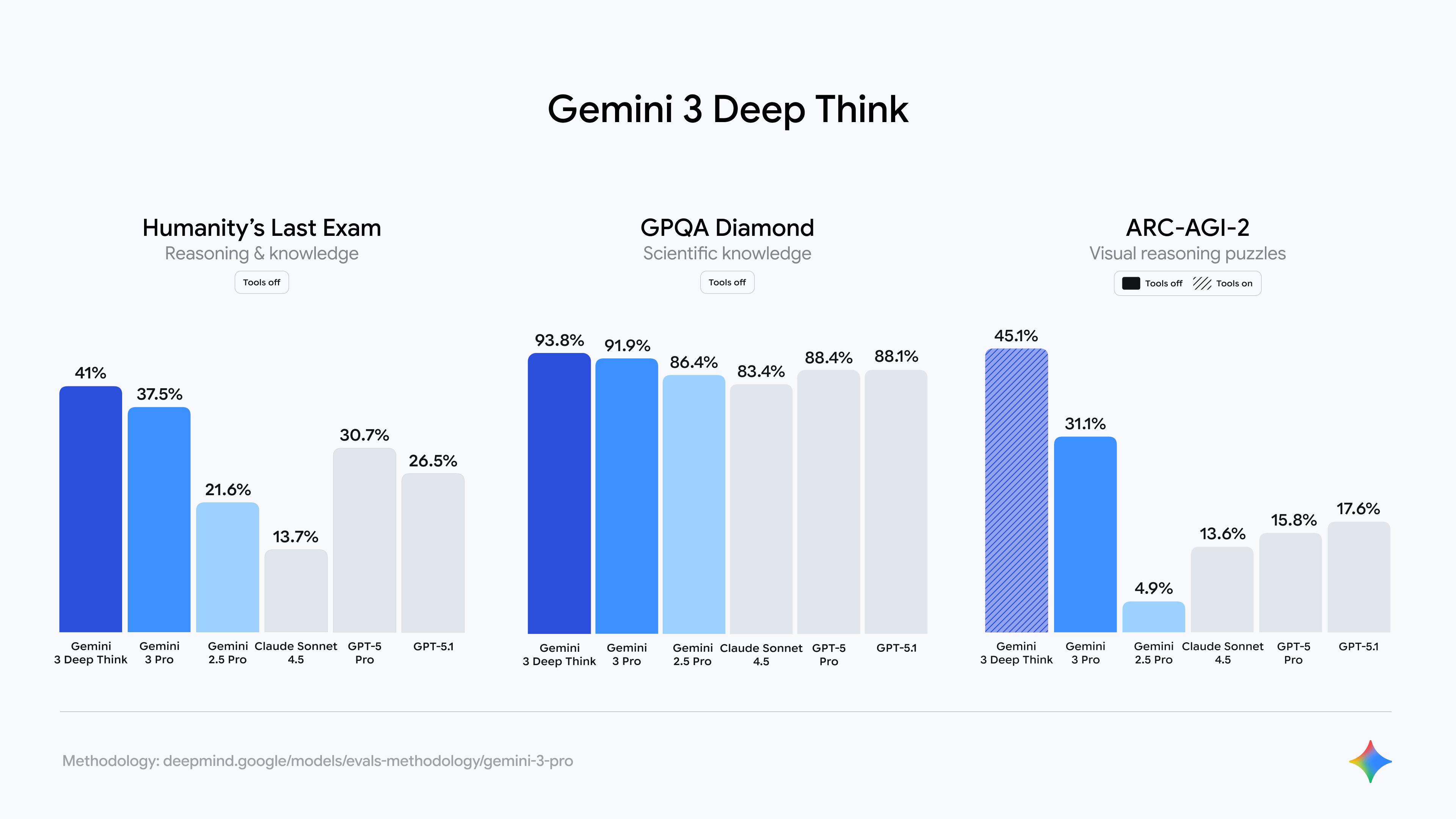
| Deep Think 模式 | 推出強化的推理模式,進一步突破智慧界限,在複雜測試(如 Humanity’s Last Exam)中的表現優於 Gemini 3 Pro。 |
4. Gemini 3 具備哪些核心功能和技術優勢?
最先進的推理能力 (State-of-the-art reasoning):專為掌握深度和細微差異而設計,提供簡潔且具真知灼見的回覆。
世界領先的多模態理解 (World-leading multimodal understanding):能夠跨文字、圖像、影片、音訊,甚至是程式碼進行推理,並在多模態理解基準測試上創下新高。
改進的代理式能力 (Improved agentic capabilities):能同時處理多步驟任務,並具備更好的工具使用能力,可以建構更有助益且智能的個人 AI 助理。
代理式編碼與 Vibe Coding:是 Google 迄今為止最強大的 Vibe coding 模型,能將高階想法(如草圖和提示)轉化為豐富且互動性的應用程式。
長脈絡視窗:支援 100 萬個詞元,適用於處理大型資料集。
5. 目前 Gemini 3 的主要問題和挑戰有哪些?
Gemini 3 目前仍有以下幾點限制或需注意的事項:
Deep Think 模式的可用性:Gemini 3 Deep Think 模式目前需要額外時間進行安全評估,先開放給安全測試人員使用,預計在接下來幾週內才會向 Google AI Ultra 訂閱用戶開放。
API 參數衝突:在 API 中,無法在同一個要求中同時使用新的
thinking_level和舊版thinking_budget參數,這麼做會傳回 400 錯誤。圖片區隔功能:Gemini 3 Pro 不支援圖片區隔功能(傳回物件像素層級遮罩)。如果工作負載需要此功能,建議繼續使用 Gemini 2.5 Flash。
工具支援限制:在 Gemini 3 支援的工具中,目前不支援 Google 地圖和電腦使用。
溫度設定警告:建議將溫度參數維持預設值 1.0。變更溫度(尤其設為低於 1.0)可能會導致非預期的行為,例如迴圈或複雜工作效能降低。
6. Gemini 3 如何處理多模態輸入(文字、影像、音訊)?
Gemini 3 是處理複雜多模態理解的最佳模型之一,能夠無縫整合文字、圖像、影片、音訊和程式碼等資訊。
圖像與文件:Gemini 3 Pro 在文件理解方面表現優異,能超越簡單的 OCR (光學字元辨識),進行複雜的文件理解和推理。在複雜圖像推理基準 MMMU-Pro 上得分 81.0%。
影片:能夠捕捉高影格率的快速動作,並具備長脈絡回溯能力,可從數小時連續鏡頭中合成敘事並精確定位細節。在影片理解基準 Video-MMMU 上得分 87.6%。
API 粒度控制:開發人員可透過
media_resolution參數,對多模態視覺處理作業進行精細控制,選項包括low、medium或high,這會影響模型的權杖用量和延遲時間。
7. Gemini 3 代理能力與生成式介面具體是什麼?怎麼應用?
代理能力 (Agentic Capabilities):
定義:指模型能夠可靠地遵循複雜指令,執行同步、多步驟任務,並改進工具使用。這是將 AI 輔助從工具箱中的一項工具,轉變為積極合作夥伴的關鍵。
應用:
開發者:透過 Google Antigravity(新的代理開發平台),代理人可以代表開發者自主規劃並執行複雜的端對端軟體任務,例如建構功能、UI 迭代或修復錯誤。
日常任務:Gemini Agent(一項實驗性功能)可處理多步驟任務,例如根據電子郵件中的細節規劃旅遊或預訂服務,或整理 Gmail 收件匣。
生成式介面 (Generative Interfaces/Generative UI):
定義:這是一種新類型的使用者介面,可即時根據使用者的提示動態生成,以設計出最適合特定查詢的響應。它利用 Gemini 3 強大的推理和代理編碼能力實現。
應用:
視覺版面 (Visual layout):生成沉浸式、雜誌風格的視圖,包含圖片和模組,例如用於規劃羅馬 3 日遊的視覺行程。
動態視圖 (Dynamic view):即時設計和編寫自訂使用者介面 (UI),以呈現互動式體驗,例如詢問梵谷畫廊時,會收到可點擊、滾動和學習的互動式回覆。
互動式工具與模擬: 即時編寫自訂模擬或工具。
▪ 案例: 詢問「三體問題的物理學」,獲得可操縱變數的互動式模擬。研究「抵押貸款」時,模型會客製化互動式貸款計算器。
8. Gemini 3 在實務上有哪些應用場景和案例?
Gemini 3 廣泛應用於多個領域,包括:
軟體開發:
- Vibe Coding:將高階想法(如單一提示)轉化為功能齊全的應用程式,例如編寫一款具備豐富視覺效果的復古 3D 太空船遊戲。
- 生產力提升:在 GitHub Copilot 的早期測試中,解決軟體工程挑戰的準確度比 Gemini 2.5 Pro 高出 35%。
- 設計轉譯:在 Figma Make 中,模型能以精確度轉譯設計並生成廣泛且富有創意的樣式和互動。
企業與法律:
- 知識應用:協助 Box AI 解釋和應用機構知識。
- 法律推理:在 Thomson Reuters 的評估中,在法律推理和複雜合約理解方面有顯著進展。
多模態處理:
- 會議與文件:準確轉錄 3 小時多語言會議並具備優異的說話者識別能力;從低品質文件照片中提取結構化數據,表現優於基準模型 50% 以上。
9. Gemini 3 的核心用途是什麼?怎麼用?
Gemini 3 的核心設計是幫助用戶實現 3 大目標,包括學習、構建與規劃等用途:
學習任何事物 (Learn anything):
- 透過結合其最先進的推理、視覺和空間理解能力,以及 100 萬 Token 的脈絡長度,幫助使用者以最適合自己的方式學習。
- 應用案例:解讀並翻譯不同語言的手寫食譜;分析學術論文或長講座影片,並生成互動式單字卡或視覺化圖表的程式碼;分析匹克球比賽影片,找出可改進之處並生成訓練計畫。
建構任何事物 (Build anything):
- 透過卓越的 Vibe coding 和代理編碼能力,將想法從草圖和提示轉化為互動工具和體驗。
- 應用案例:透過 Vibe coding 打造更豐富、更具互動性的網頁 UI 和應用程式;使用單一提示編寫複雜的互動式 3D 遊戲。
規劃任何事物 (Plan anything):
- 透過提升長期規劃能力和工具使用的一致性,協助委派多步驟專案,比以往更快完成任務。
- 應用案例:協助規劃旅遊行程;整理收件匣。
10. 在搜索引擎中,Gemini 3 是如何帶來生成式介面與互動工具的體驗?
在 Google 搜尋的「AI 模式」中,Gemini 3 利用其多模態理解和強大的代理編碼能力,解鎖了客製化的生成式使用者介面 (Generative UI) 體驗。
動態生成:Gemini 3 會分析查詢,並即時動態生成最理想的視覺版面,其中包含視覺元素,如圖像、表格和網格,使輸出結果更清晰且可操作。
即時編碼互動工具:當模型判斷互動工具(例如模擬情境)有助於理解主題時,它會利用其生成能力即時編寫自訂模擬或工具,並將其添加到回覆中。
舉例來說:詢問三體問題的物理學時,可以獲得一個互動式模擬,讓使用者操縱變數並觀察重力作用;研究抵押貸款時,模型可以在回覆中為使用者客製化一個互動式貸款計算器。
11. Gemini 3 如何協助日常生活與工作流程的自動化,如旅遊規劃與收件匣整理?
Gemini 3 Pro 展現了更好的長期規劃能力,可以透過結合更深度的推理和改進後更一致的工具使用,代表能執行更複雜、多步驟的工作流程。
以下舉兩個常見案例:
收件匣整理:Google AI Ultra 訂閱用戶可以在 Gemini 應用程式中試用 Gemini Agent,它能處理多步驟任務,例如整理收件匣,優先處理待辦事項並草擬回覆供使用者批准。
旅遊規劃:Gemini Agent 可以接受精確指令,例如:「研究並協助我預訂下週旅行的中型 SUV,預算在每天 $80 以下,並使用我的電子郵件中的細節。」Gemini 將會定位的航班資訊、比較符合預算的租賃選項並準備預訂。

12. Gemini 3 的隱私與資料安全如何保障?
Gemini 3 是 Google 迄今為止最安全的模型,並經歷了 Google AI 模型中最全面的安全評估。
在安全保障方面,Gemini 3 模型展現了以下 3 個特性:
- 減少阿諛奉承的傾向。
- 增強對提示注入 (prompt injections) 的抵抗力。
- 改善針對網路攻擊濫用的防護。
13. 如何使用 Gemini 3 的 API?
Gemini 3 Pro (模型 ID:gemini-3-pro-preview) 可透過 Gemini API 在 Google AI Studio 和 Vertex AI 中使用。開發者可以使用 Python、JavaScript 或 REST 等方式呼叫模型。
Gemini 3 也引入了新的參數以控制模型行為和延遲時間,包括:
思考層級 (
thinking_level):控制模型在產生回覆前內部推理過程的深度。預設為high,以進行最深入的推理。媒體解析度 (
media_resolution):精細控制多模態視覺處理,選項包括low、medium、high,影響權杖用量和延遲時間。思想簽章 (
thoughtSignature):用於在 API 呼叫之間維持推理情境。在函式呼叫的嚴格驗證中,必須將這些簽章傳回模型,以確保模型維持推理能力。
14. 遇到常見錯誤碼怎麼排除?
開發者如果常見錯誤碼,排除與注意事項可參考以下表格:
| 錯誤類型/情境 | 排除方式與注意事項 |
|---|---|
| 400 錯誤 | 避免在同一個要求中同時使用 thinking_level 和舊版 thinking_budget 參數。 |
| 函式呼叫的 400 錯誤 | 在函式呼叫中,API 會對思維簽章 (thoughtSignature) 實施嚴格驗證。如果模型的回覆包含簽章,必須在下一個回合傳回它,否則會收到 400 錯誤。 |
| 從舊模型或自訂函式呼叫遷移 | 如果從其他模型遷移對話記錄,或插入非 Gemini 3 生成的自訂函式呼叫(無法取得有效簽章),請在 thoughtSignature 欄位中填入特定的虛擬字串 "context_engineering_is_the_way_to_go" 來略過嚴格驗證。 |
| 溫度設定 | 雖然不是錯誤碼,但強烈建議將溫度參數維持預設值 1.0。變更溫度(尤其設為低於 1.0)可能會導致非預期的行為,例如迴圈或複雜工作效能降低。 |
15. Gemini 3 是否需要付費?有免費版?API 限制和配額是?
Gemini 3 Pro 的費用取決於的使用平台:
Google AI Studio (免費試用)
- 可以在 Google AI Studio 中免費試用 Gemini 3 Pro 模型,但有速率限制。
Gemini API (付費方案)
- 目前 Gemini API 中的
gemini-3-pro-preview沒有免費方案。 - 開發人員可透過 Gemini API 在 Google AI Studio 和 Vertex AI 中使用此模型。
- 定價 (Gemini 3 Pro 預覽版):價格以每 100 萬個權杖為單位,所列價格為標準文字價格,多模態輸入費率可能有所不同。
- 目前 Gemini API 中的
| 權杖數量 | 輸入 (Input) 價格 (每 100 萬權杖) | 輸出 (Output) 價格 (每 100 萬權杖) |
|---|---|---|
| 20 萬個權杖或以下 | $2 美元 | $12 美元 |
| 超過 20 萬個權杖 | $4 美元 | $18 美元 |
- 訂閱服務 (使用限制)
- Google AI Plus、Pro 和 Ultra 訂閱用戶將繼續享有更高的使用限制(主要指在 Gemini App 或 Search 的 AI 模式中)。
API 限制與配額 (脈絡長度與技術規格)則可參考以下表格整理:
| 項目 | 規格與說明 |
|---|---|
| 最大脈絡窗口 (輸入) | 支援 100 萬個詞元 (tokens) 的輸入脈絡窗口。 |
| 最大輸出長度 | 最多支援 64,000 個詞元的輸出內容。 |
| 知識截點 | Gemini 3 Pro 的知識截止日期為 2025 年 1 月。 |
| 頻率限制 | 如需詳細的速率限制、批次定價和其他資訊,應參閱模型頁面。 |
| 脈絡快取 (Context Caching) | 支援脈絡快取。如要啟動快取,至少需要 2,048 個權杖。 |
| 媒體解析度影響 | 較高的媒體解析度 (media_resolution_high) 雖然能讓模型辨識細小文字或細節,但也會增加權杖用量和延遲時間。 |
資料來源:Google;本文初稿由 AI 協助整理,編輯:林柏源